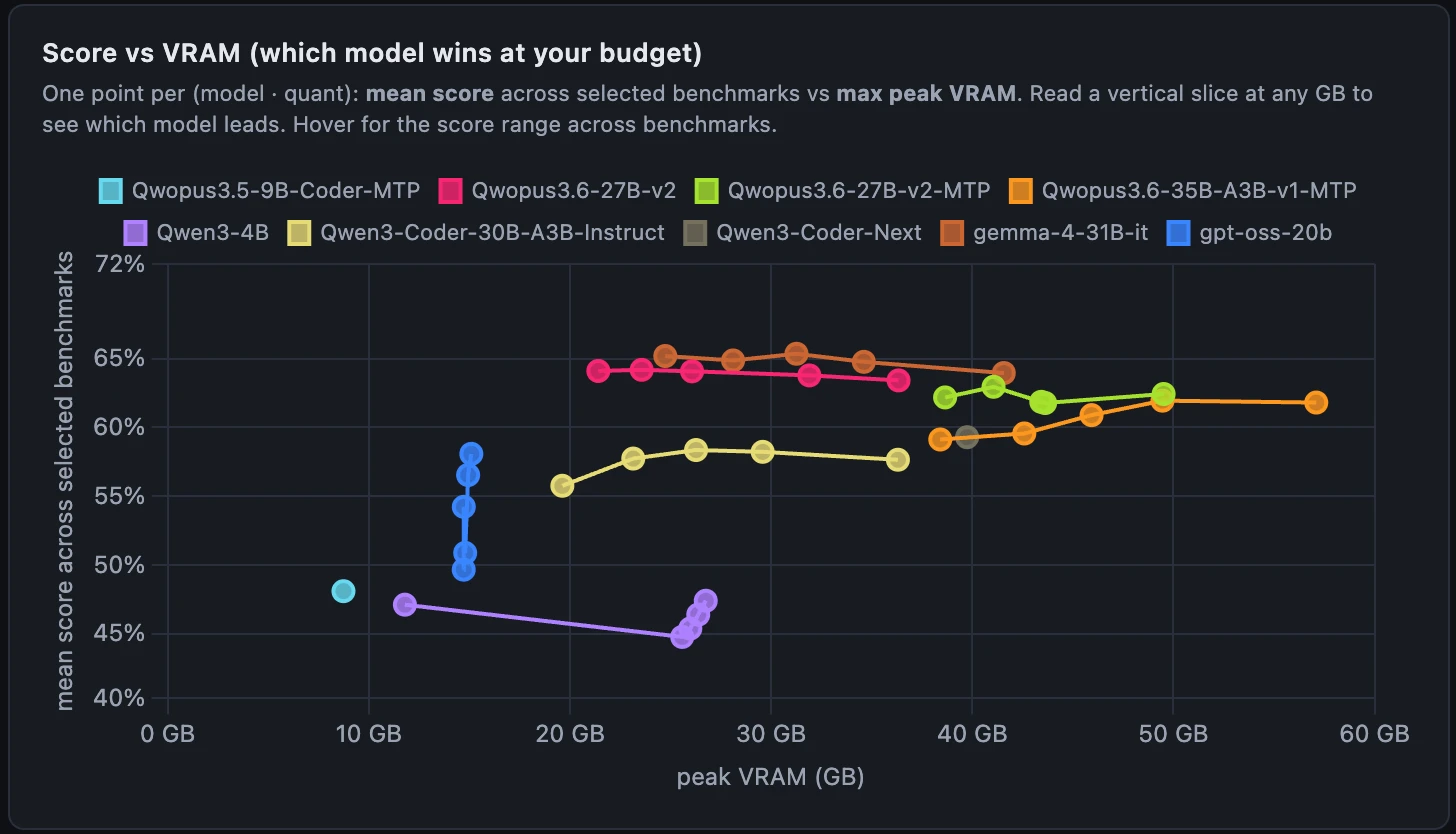
Local Model Benchmarks
Open LLMs, benchmarked locally on a single NVIDIA RTX 6000. The goal is to quantify how each model and each quantization of it performs on real coding and reasoning tasks, so you can pick the best model to run locally for your VRAM budget. Set your GPU's memory with the Max VRAM filter below, then compare scores per task and watch how quality holds up as the quants get smaller.
Technologies
local llm
benchmarks
qwopus
qwen
gemma
gpt-oss
Other Projects
Rip Reader
Speed reading accessible to anyone...
RockPaperScissors.pro
Play rock paper scissors with your friends online...
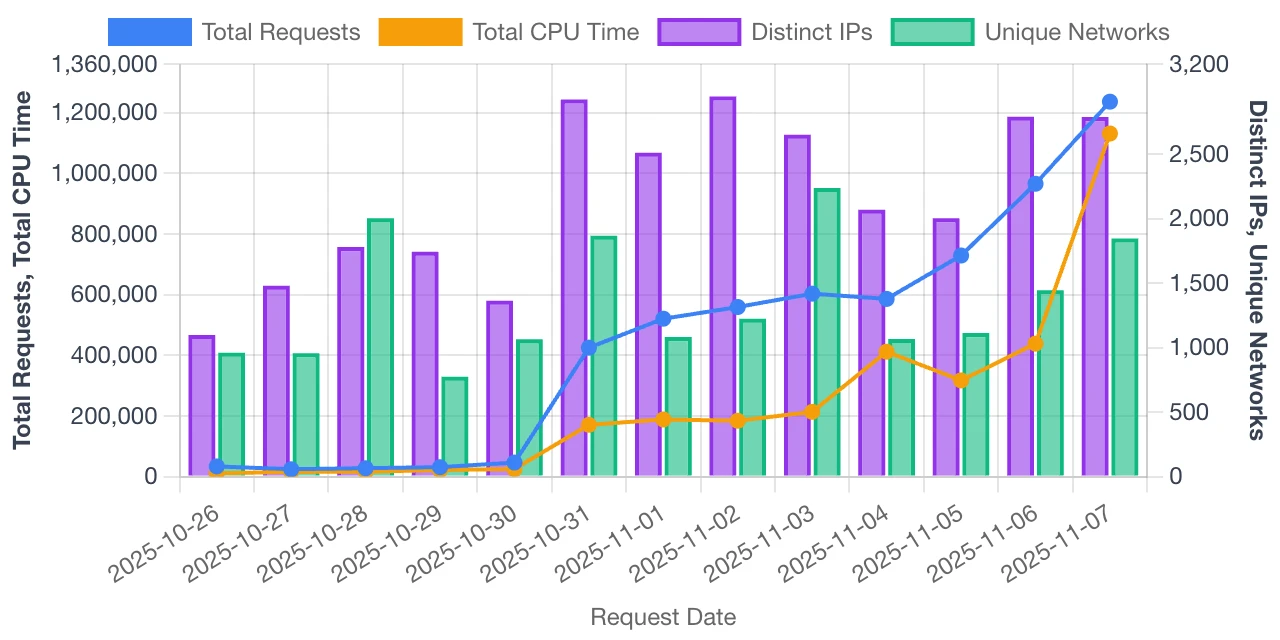
Simple Data Charts
Quickly produce bar, line, pie or scatter plots from copy and pasted data all in the browser....