Abuse from the Amazon IP networks never end
Amazon currently owns over 20,000 IP subnets containing over 221 million IPs. Differentiating legitimate traffic from abusive is difficult, attackers have practically unlimited IP addresses at their fingertips.
One of the hardest parts of hosting websites on the internet today is keeping servers smoothly running for legitimate users. Crawlers, scrapers and vulnerability scanners are all constantly attacking every website on the internet. Trying to distinguish the good vs bad traffic from Amazon is always a difficult thing. Here is what I woke up to the other day.
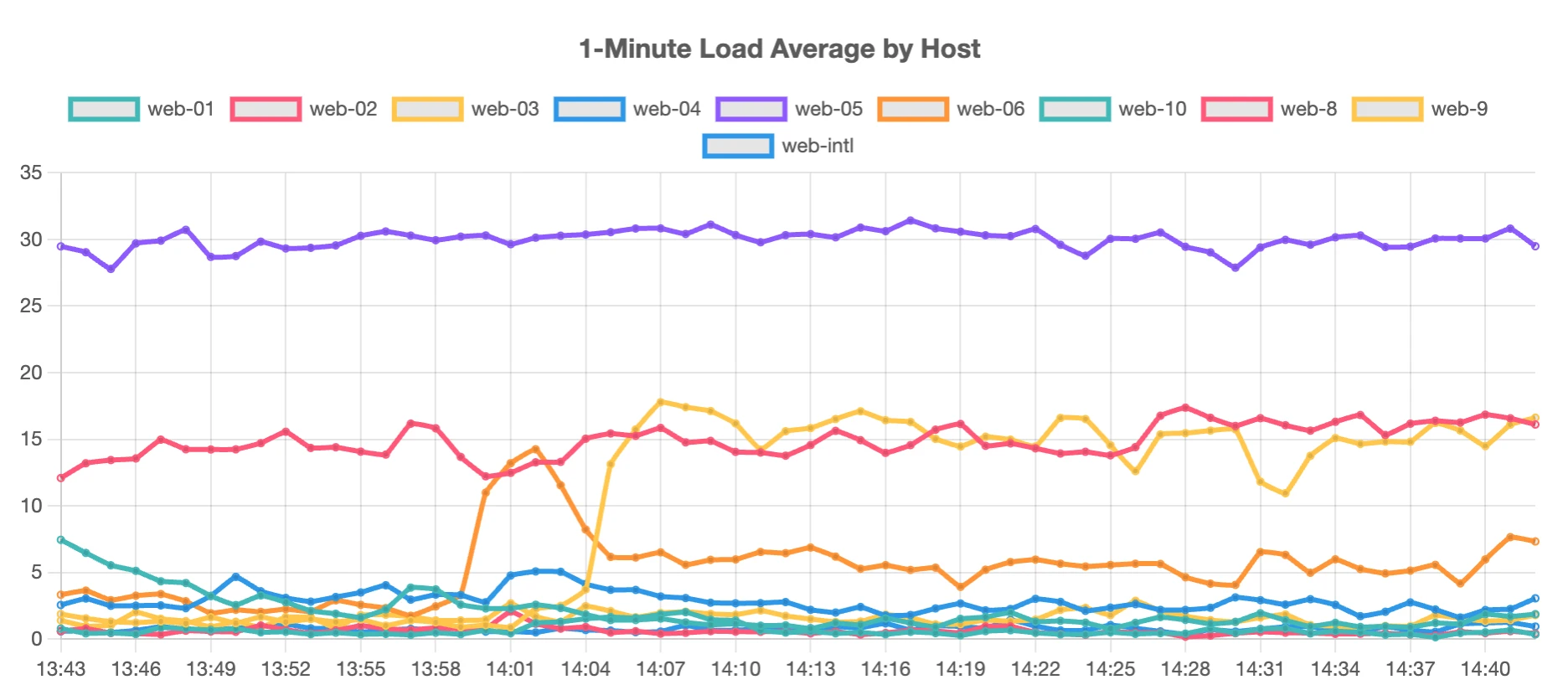
4 separate servers were getting hammered, so I had to check what the source of the trouble was from. I have a script that reads the nginx access logs on the server, grouping requests by ip address to determine the number of requests sent and the total seconds of server time used for that IP's requests.
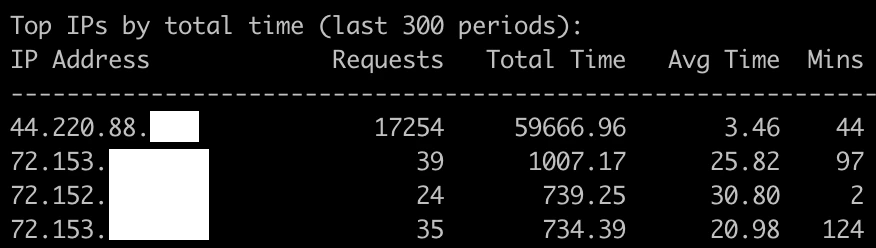
The first server I checked had received 17k requests and consumed just shy of 60k seconds of server time over the course of 44 minutes (6.5 requests per second, 22 seconds of CPU per second). For comparison I left the next heaviest user, who used 1k seconds of server time over the past 97 minutes. This 44.220.88.0/24 is owned by Amazon. User Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36.
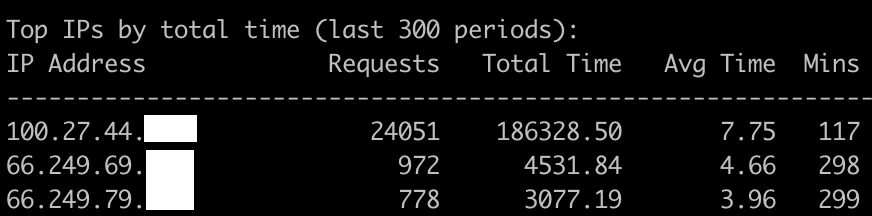
The second server I checked had received 24k requests and consumed 186k seconds of server time over 117 minutes (3.4 req/second, 26.5 seconds of CPU/sec). The next heaviest IP's were both Google crawling other sites, sending about 3 requests per minute consuming 15 seconds of CPU/minute. This 100.27.44.0/24 is owned by Amazon. User Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36.
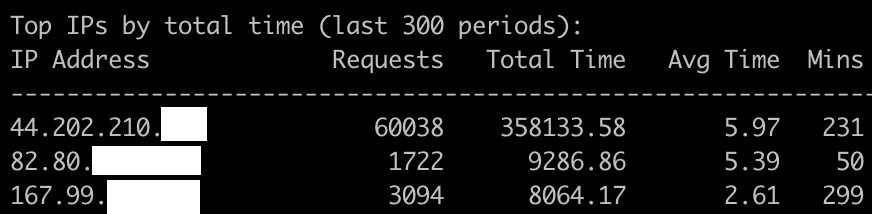
The third server was the worst by far with over 60k requests consuming 358k seconds of server time over 231 minutes (4.3 req/second, 25.8 seconds of CPU/sec). The next heaviest user on this server was only 34.4 req/min with 3 seconds of CPU/second. This 44.202.210.0/24 is owned by Amazon. User Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36.
The problem here is that these IP's are random and change every day. I know what you're thinking, fail2ban will solve this quickly. The difficult part is legitimate users often get blocked due to high usage. Perhaps there is still some reasonable way to handle this with fail2ban, but this is just 1 of a few types of abusive scrapers and fail2ban would not handle the other two.
For the sake of categorizing these abusive scrapers, lets call this Saturating Amazon Cloud Scraper, since they use up all available resources for as long as they can. This user agent is consistent, but just today alone I received 1400 requests from this user agent across over 600 different IPs. The vast majority of these are not abusive, only these 4 were problematic.
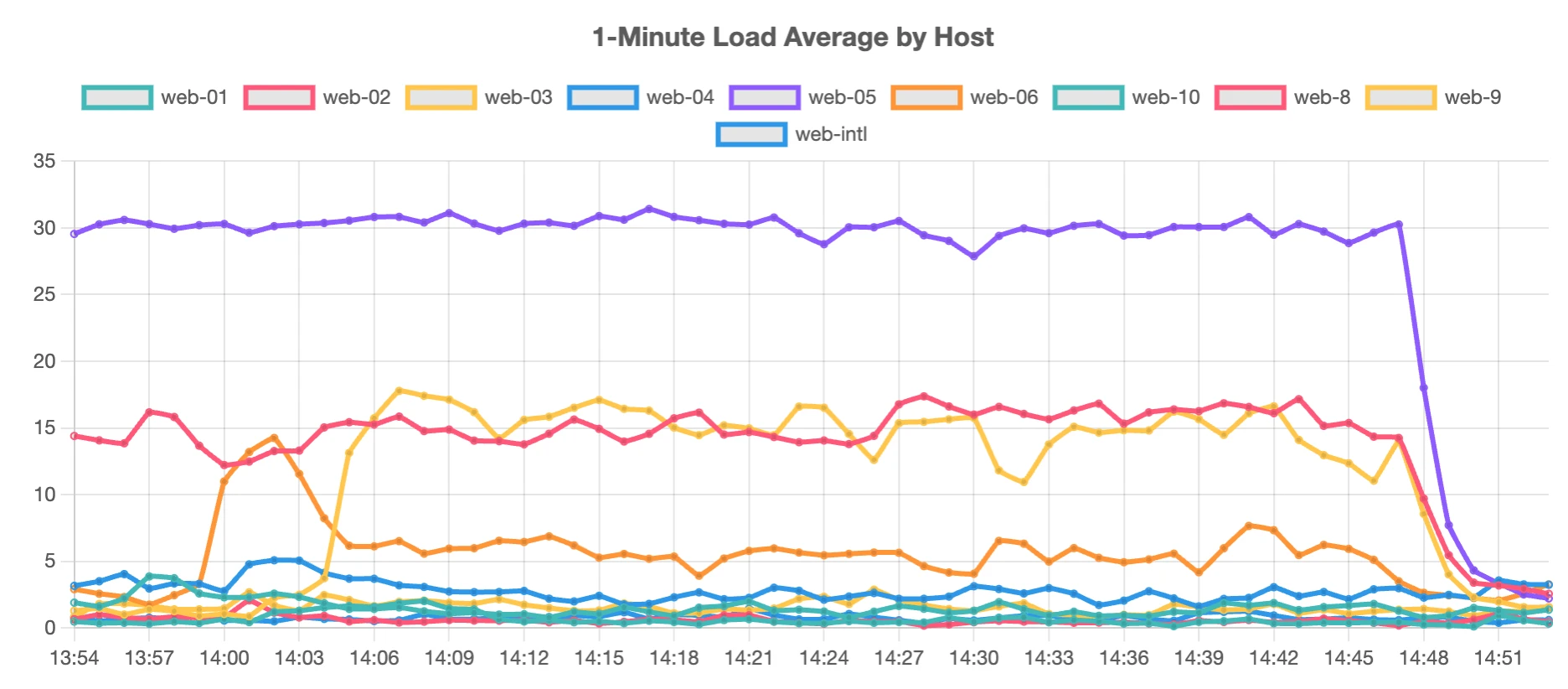
Once the 4 IP's were blocked, back to normal.
While I am sitting here writing this, another spike came in.
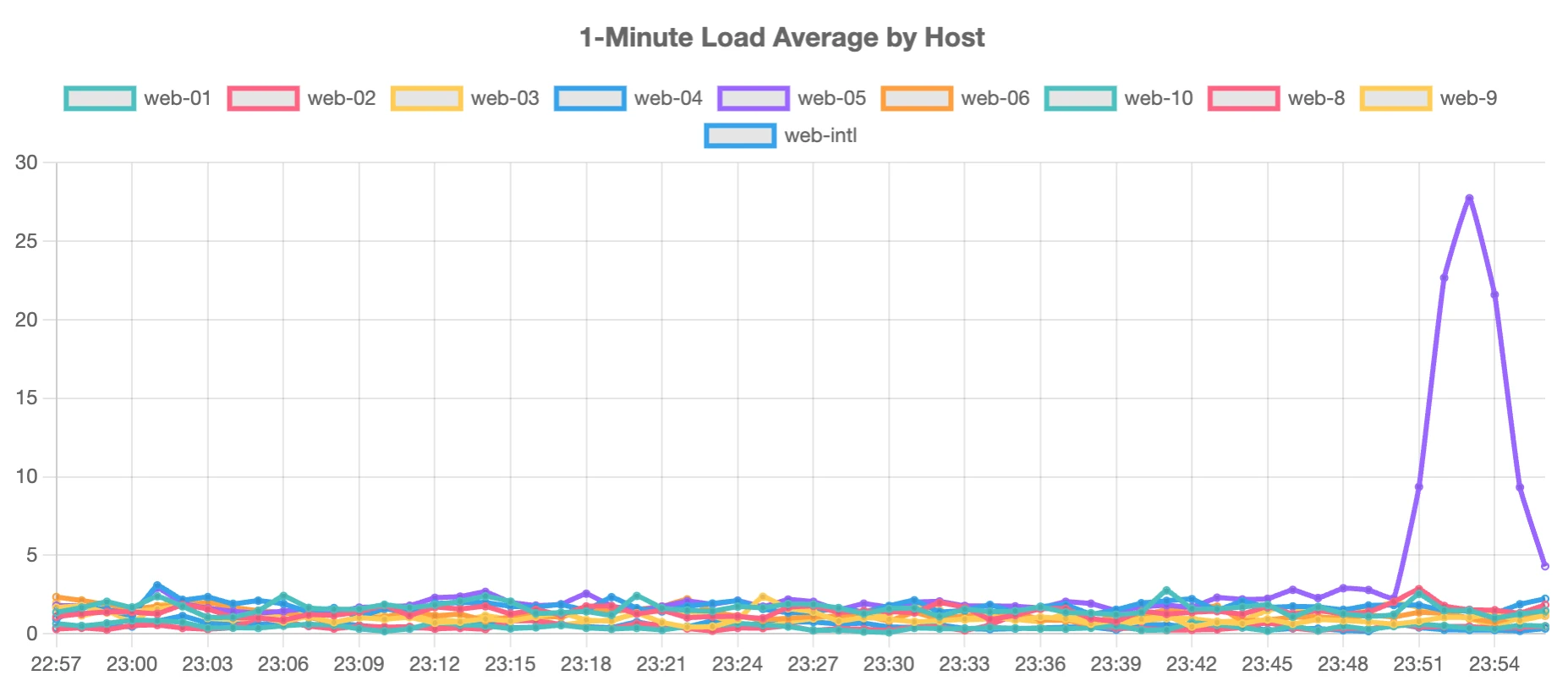
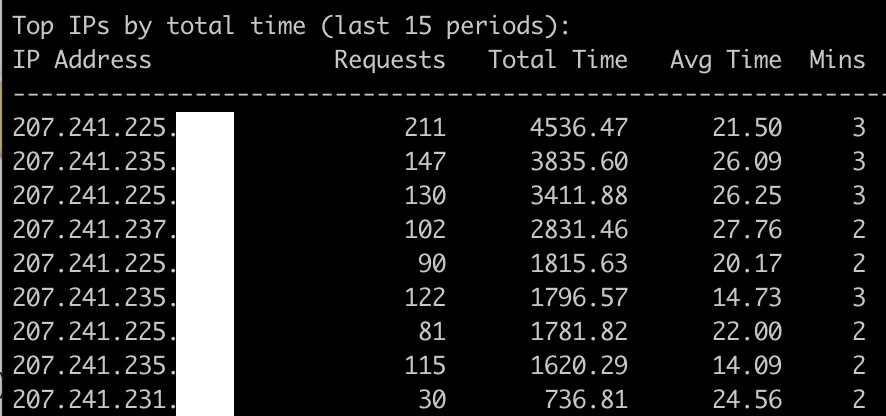
In this case it ended up being 10 IP's across the 207.241.224.0/20 subnet. Each IP ended up around 1.2 req/sec with 25 seconds of CPU per second. In this case though, they properly identified themselves with a real user agent. This 207.241.224.0/20 is owned by the Internet Archive. User Agent: Mozilla/5.0 (compatible; archive.org_bot +http://archive.org/details/archive.org_bot) Zeno/0458982 warc/v0.8.90.
This is a good example of traffic that would be blocked by fail2ban for sure, but I am inclined to allow since it's serving a positive purpose and also is not anonymously faking user agents. They also do not sustain their requests for hours, just 3 minutes in this case.